こんにちは、ニケです。
2026年5月6日(水)に開催される 生成AIなんでも展示会 Vol.5 に出展します。
今回の展示テーマは、AIキャラにゲーム実況とゲームプレイをさせてみる です。
「完成した最強プロダクトを見てください!」というよりは、AIキャラ × ゲーム実況 × AIプレイをどう作るかの試行錯誤を見せる展示になると思います。
今回の記事は、以下の記事を展示会向けに短くまとめたものです。
細かい技術的な話や、ゲームごとの状態取得については、こちらの記事で詳しく書いています。


以前の展示
実は以前にも、生成AIなんでも展示会で似たテーマの展示をしていました。
そのときは、AIキャラがゲームをプレイして、さらに実況もしているように見せるシステムです。
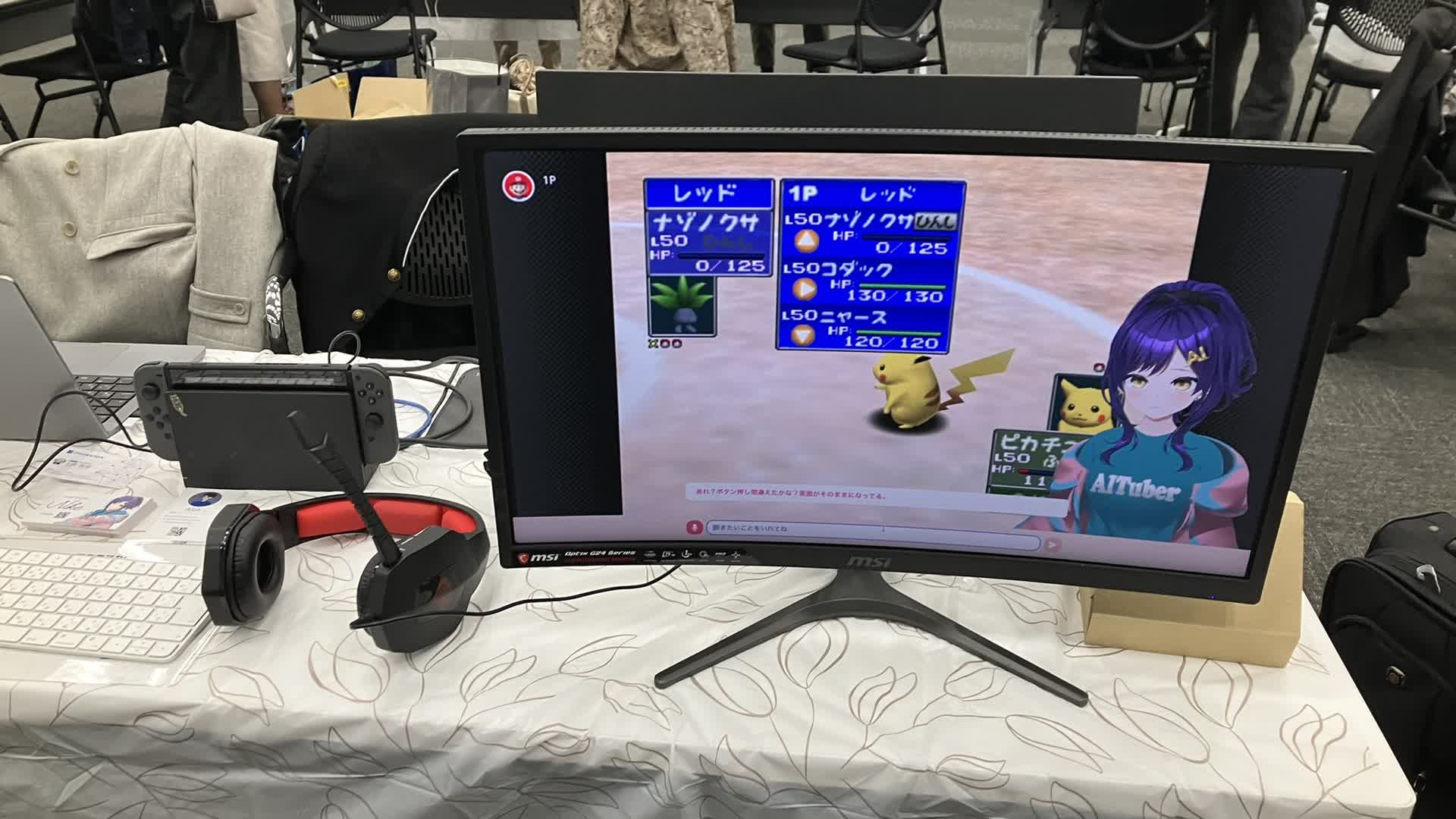
当時の構成はかなり力技でした。
Nintendo Switch のゲーム画面をスクリーンショットとして取得し、それをマルチモーダルLLMに渡します。
LLMが画面を見て「今どういう状況か」を解析し、そこから 次の一手 と 実況セリフ を生成する、という流れです。
AIが画面を見て、行動を決めて、喋る。
字面だけ見るとかなり夢がありますが、現実はそこそこ厳しいものでした。
旧方式の課題
旧方式を簡単に図にするとこのような感じになります。
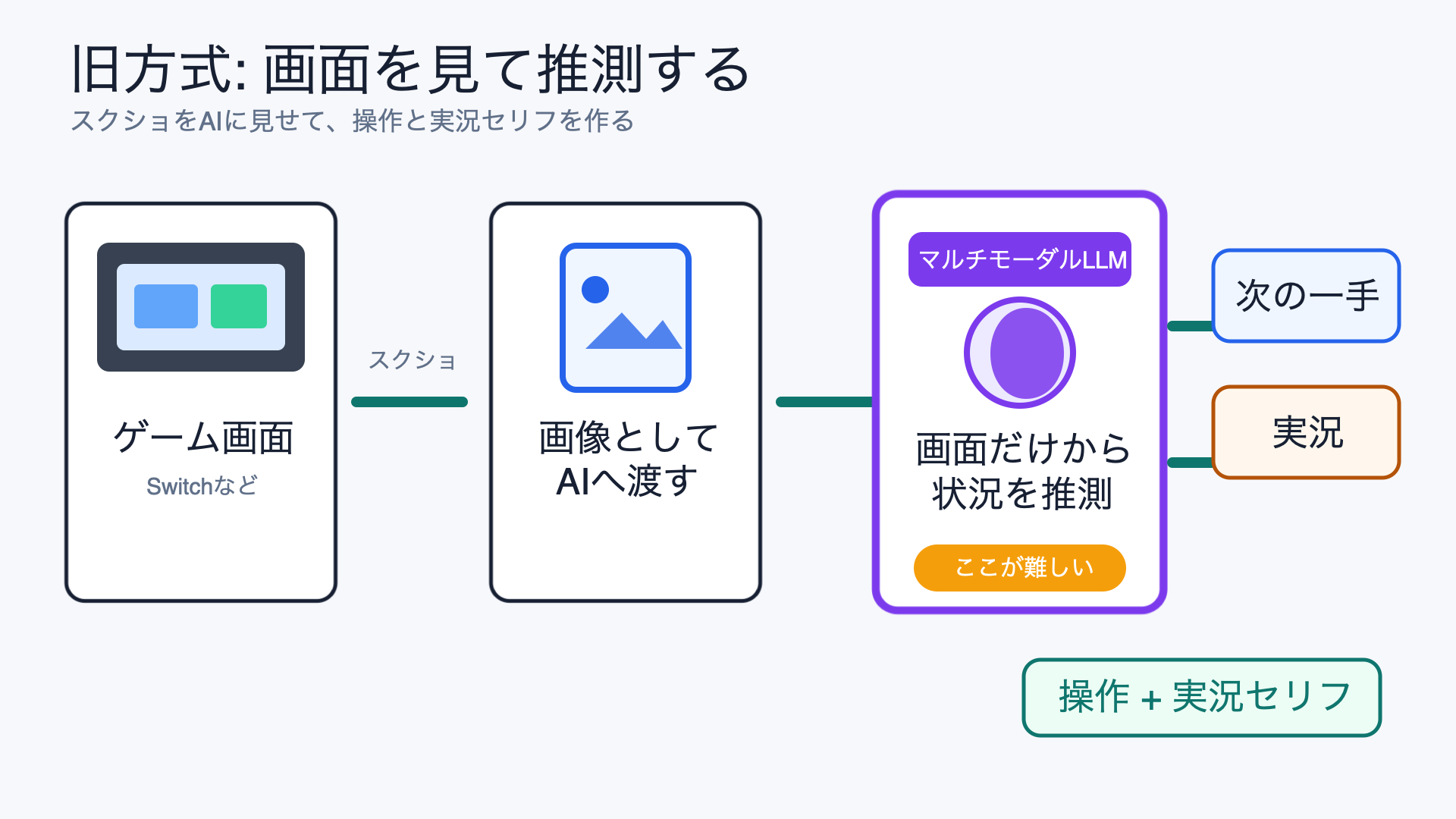
画面を見る方式。
この構成の大きな課題は、遅いこと と 精度が安定しないこと でした。
当時のマルチモーダル処理では、画面を渡して状況を読ませるだけで20秒ほどかかっていました。
そこからセリフ生成、音声合成、再生まで入るので、実況としてはかなり遅くなります。
ゲーム実況なのに、今の画面を見て喋るころには、もう全然違う場面になっているのは致命的です。
もう1つの問題は、画面だけではゲーム情報を取り切れないことです。
人間なら、HP、ログ、選択肢、相手の状態、操作できるタイミングなどをなんとなく読み取り、理解することができます。
でもAIに1枚のスクショだけを渡しても、画面の一部を見落としたり、UIの意味を取り違えたりしてしまいます。
特にゲームは、映像の中に「見えているけど重要ではない情報」と「小さいけど超重要な情報」が混ざっているため、マルチモーダルLLMに全部を安定して読ませるのは思ったより大変でした。
画面を見る方式の改善案
とはいえ、画面を見る方式にも改善案はあります。
まず1つ目は、遅いことに対する解決策として、視聴者に見せるゲーム画面を遅延させる 方法です。
AIの実況生成が数秒遅れるなら、逆にゲーム映像も同じくらい遅らせて表示すれば、視聴者には実況と映像が同期して見えます。
リアルタイム性を捨てる代わりに、体験としての自然さを取りにいく発想ですね。
この案は配信としてはかなり現実的です。
OBS側で映像遅延を入れればよいので、ゲーム側を改造しなくても成立します。
2つ目は、情報が不足している場合に対する解決策として、高速なマルチモーダルモデルを使い、複数の画面情報を渡す 方法です。
最近のマルチモーダルモデルはかなり速くなっていて、昔のように毎回20秒待つ前提ではなくなってきました。
特に gemini-3.1-flash-lite-preview は、マルチモーダル込みで2秒ほどでテキスト生成が完了する驚異的な速度です。
これを利用して、発話処理中などの何もしていない裏側で、何枚かスクショを解析しておけば、次のセリフ生成時に「直近の状況」を多めに渡すことができます。
ただし、これらの方法でも限界はあります。
どれだけモデルが速くなっても、画面を見て推測している限り、見落としや誤認識は残ります。
ゲームの状態を「画像として推測する」のがそもそも難しい、という問題です。
発想の転換
そこで考えたのが、そもそもゲームの情報をテキストで入手できればよいのでは? という方向です。
画面をAIに見せて「たぶん今こういう状況です」と推測させるのではなく、ゲームの状態やログ、選べる行動をテキストやJSONとして渡します。
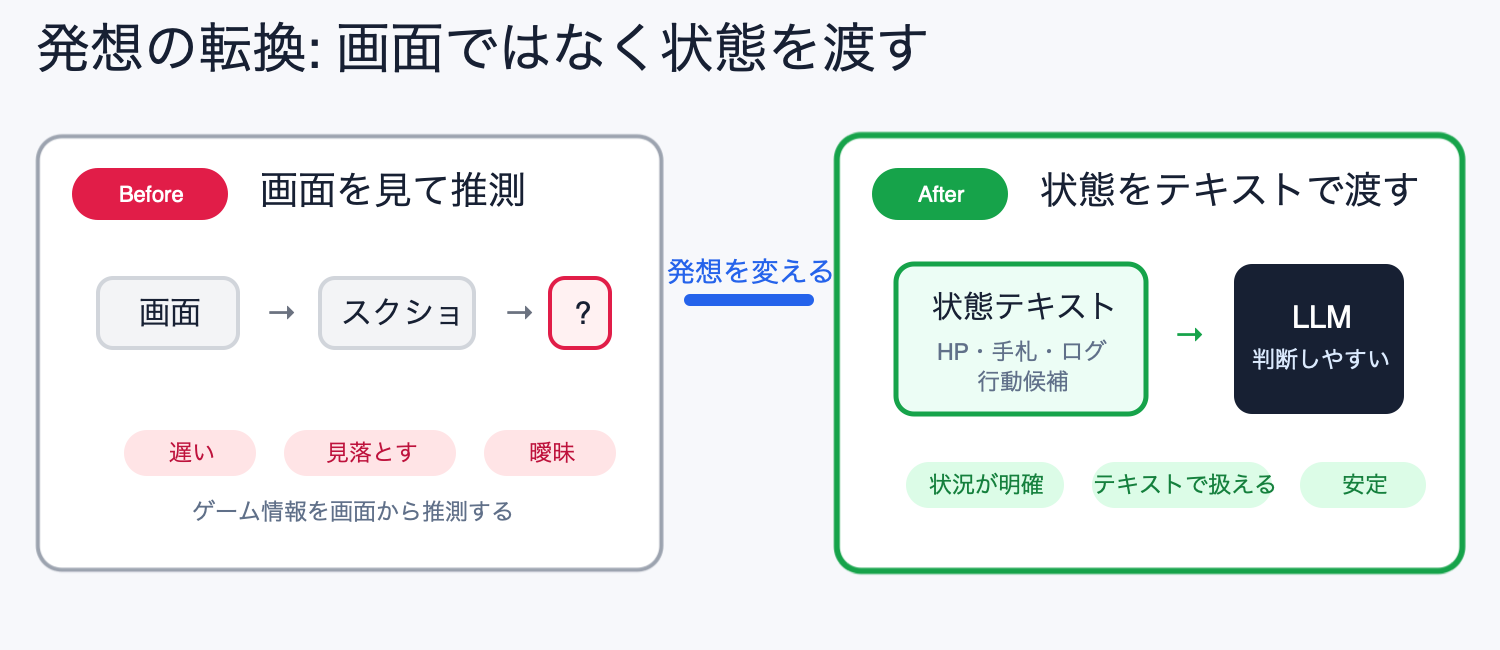
画面を見るのではなく、状態を渡す。
この方式だと、AIに渡す情報がかなり素直になります。
- 今のHP
- 手札や技
- 相手の状態
- 選べる行動
- 直前のログ
- etc...
これらの情報をそのままテキストで渡せれば、マルチモーダルで画面を読む必要がありません。
LLMはテキスト処理が本業なので、こっちのほうが自然です。
つまり、ゲーム実況だけでなく、AIプレイも同じ仕組みに寄せやすくなります。
状態を読んで、次の行動を選び、その行動をゲームに反映させることができます。
題材例1: Pokémon Showdown
この方向で分かりやすい題材が Pokémon Showdown です。
Pokémon Showdown はブラウザで動くポケモンバトルシミュレータで、対戦ログや行動候補をテキストとして扱いやすいのが特徴です。
AIに画面を見せなくても、現在のバトル状況や選べる技をテキストで渡せます。
そのうえで「次にどの技を選ぶか」を返してもらえば、プレイ部分が成立します。
さらに、その判断理由やバトルログを使えば実況セリフも作れます。
画面認識、プレイ判断、実況生成をバラバラに作るのではなく、ゲーム状態のテキストを中心に、プレイと実況を同じ流れで作れる ようになります。
題材例2: Slay the Spire
もう1つの題材が Slay the Spire です。
Slay the Spire は標準で外部APIがあるゲームではありませんが、Modを使うことでゲーム状態をJSONとして取得し、コマンドで操作できます。
カードゲームなので、今の手札、エナジー、敵のHP、敵の行動意図などが重要になります。
これらをJSONとして取れるなら、AIに渡す情報としてはかなり扱いやすいです。
あとはAIが「どのカードを、どの敵に使うか」を決めて、それをコマンドとして返せばよい。
もちろん、強くプレイさせるのは別問題ですが、少なくとも画面認識に失敗して詰まる問題はかなり減らせます。
展示で見てほしいこと
今回の展示では、AIがゲームをプレイしながら実況している様子 を見てもらう予定です。
題材としては Pokémon Showdown と Slay the Spire を使います。
どちらもターン制で状況が分かりやすいので、AIがどういう情報を得て、どう判断しているのかを眺めやすいはずです。
観覧用の詳しい資料も用意する予定なので、気になるところがあれば資料を見ながらその場で聞いてもらえればと思います。
終わりに
生成AIなんでも展示会 Vol.5 で展示する内容をまとめました。
旧方式では、ゲーム画面をスクショしてマルチモーダルLLMに読ませ、次の一手と実況セリフを生成していましたが、遅さと精度の問題がありました。
そこから、画面遅延や高速マルチモーダルという改善案を試しつつ、最終的には「ゲーム状態をテキストで取れればよいのでは?」という方向に進んでいます。
また、最近はLLMの進化もあり、自作ゲームというのもかなり現実的になってきました。
AIが遊びやすいようにゲーム側を設計する、という方向もこれから面白くなっていきそうです。
まだまだ私も試行錯誤の途中です。
ゲームを理解して、プレイして、実況する、そんなAIキャラクターの未来を一緒に見ていけたら嬉しいです。
展示会に来る方は、ぜひ見ていってください。
何でも質問してOKです!
宣伝
普段XでAIツールやAIキャラクターについての発信をしているので、興味があったらフォローしていただけると大変喜びます🙇♀️