こんにちは、ニケです。
皆さん、AIにゲームを遊ばせて実況までやらせてみたいと思ったことはありますか?
私は以前からそういうのを作って遊んでいて、2024年の11月には何でも生成AI展示会で展示したこともあります(詳細は以下のnoteからどうぞ)。

この記事は、AI実況を作ってみたい個人開発者や、AITuber的な配信構成を考えている人向けに書いています。
このシステムでは、プレイ担当 と 実況担当 の2つ仕組みが連携して動く構成でした。
プレイ側がゲーム画面を見て操作を決め、その情報から実況側が場面にあったリアルタイムのコメントを生成して喋る、という分業です。
展示会で動かすには何とか成立したものの、今になって振り返るといろいろと無理のある作りでした。
今回は、あれから1年半くらい経って状況がかなり変わったので、最近ならこう作るよ という3つのやり方をまとめていこうと思います。
昔の構成と、何が課題だったか
まず当時の実況の仕組みを簡単におさらいします。
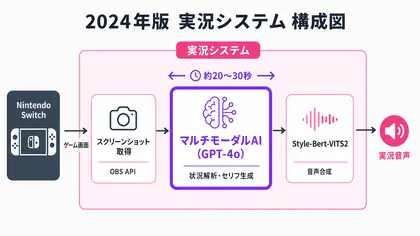
ゲームを操作するプレイシステムが別に動いていて、実況システムはそのログを元にセリフを生成する、という2段構えでした。実況システムの流れはこんな感じです。
- ゲーム画面のスクリーンショットをマルチモーダルAI(GPT-4o)に渡す
- 状況を解析してもらい、その場面にあった実況セリフを生成
- Style-Bert-VITS2 で音声合成して喋らせる
以下が実際の動画です。
これで何とか成立はしていたんですが、今振り返るとかなり無理のある構成でした。
実況として最大の課題は遅さです。
画面を見てから実際に発話するまでに、おおよそ20〜30秒かかっていました。そのほとんどがマルチモーダルAIの処理時間です。
実況なのに、今の場面を見てから発話するまでに数十秒かかる。
その間に盤面は間違いなく変わってしまいます。
コストの問題もありました。マルチモーダルAPIの料金が1時間あたり10数ドル。
配信で何時間も回したら、それだけで高額のAPI代になります。
というわけで、ここからが本題です。これを2026年現在ならどう解決するか、という話をします。
今回紹介する3つのやり方のうち、案1と案2は人間がプレイする映像にAI実況を付けるアプローチです。案3はAIがプレイも実況も両方こなす、より踏み込んだアプローチです。
案1: ゲーム映像と音を遅延させる
1つ目は、ちょっと逆転の発想みたいなやり方です。
AIを速くするんじゃなくて、視聴側の映像と音をAIの応答時間分だけ遅らせます。
AIがマルチモーダルで画面を解析して返答を生成するのに数秒かかるなら、プレイ映像と音声を同じだけ遅延させて配信すればOK、という考え方です。
視聴者からすると、AIの実況とゲーム画面がちゃんと噛み合っているように見えます。
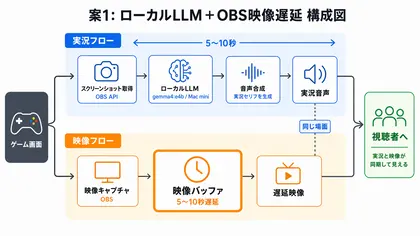
遅延の具体的な秒数はモデルによりますが、最近発表された gemma4:e4b を Mac mini で試したところ5〜10秒ほどでした。
ローカルモデルでこの速度が出るのは最近の話で、少し前なら同じことをするにはクラウドAPIに頼るしかなかったと思います。
遅延部分は自前で映像バッファを組まなくても、OBSの組み込み機能だけでいけます。
返答までの時間は定まっていないので、この映像では固定で8秒遅延させています。
コツは平均応答時間よりも少し短めに設定することです。映像の状況より少し早く話し始めてしまっても、発話している間にその場面に到達するため、視聴者からは違和感なく見えやすくなります。
この方式のいいところは、遅延を入れるだけなので既存の構成をほぼ変えなくていい ところです。
ローカルLLMで完結すれば API 課金も発生しないので、長く運用したい個人開発者にはうれしい組み合わせですね。
逆にマイナスな点は、リアルタイム性を捨てているところ。
コラボ配信のように相手の映像とリアルタイムで同期が必要な場面には向きません。
案2: 最新の高速マルチモーダルにそのまま投げる
2つめは、真っ直ぐな解決策です。
単純に、最新の速いマルチモーダルモデルを使います。
ここ半年くらいで、各社のマルチモーダルモデルがとにかく速くなっています。
私が最近試して一番手応えがあったのは gemini-3.1-flash-lite-preview で、画像込みでも 速いときは2秒ほどで返答が返ってきます。
旧記事で20秒かかっていた処理が一桁秒で終わるわけですね。技術の進歩すごい。
速いだけじゃなくて、回答のクオリティも昔の高級マルチモーダルより明らかに良いです。
「遅い・壊れやすい」という問題をモデルの差し替えだけで一気に緩和できます。
このパターンの強みは、旧来の構成のまま中身のモデルを差し替えるだけで済む ところです。
画面キャプチャ → マルチモーダル送信 → セリフ生成・発話、のパイプライン自体はそのまま使えるので、すでに旧構成を持っている人ならほぼ書き換えゼロでいけます。
弱点はここまで速いモデルがこれ一択なところ。
クラウドモデル依存なので、値上げされたり提供終了したりしたら一気に計画が狂う可能性があります。
応用: バックグラウンドで状況を先読みする仕組み
案2の高速マルチモーダルをベースにした、もう一歩踏み込んだ応用の話もします。
ここまで紹介してきたやり方では、セリフ生成のタイミングで渡す画像は1枚だけでした。
ただし1枚だと、ちょうど映像の途中や画面が切り替わる瞬間を切り取ってしまうケースもあり、場面によっては状況を正確に読み取れずズレたセリフが出てしまうことがあります。
そこで、発話中の空き時間を活用することにしました。
音声合成が終わって再生が終わるまでの数秒間、システムは何もしていないので、ここを使います。
具体的に以下のような仕組みを取り入れました。
- 発話中(音声合成〜再生の間)、裏で数秒ごとにゲーム画面をキャプチャしてLLMに投げる
- LLMは画像を見て、その状況を短いテキストに変換して返す
- 次のセリフを生成するとき、この「状況テキスト」をプロンプトに含める
こうすると、セリフを生成する段階で「今どういう状況か」が文字で渡せるので、画面情報を1つだけ渡していたよりも文脈にあったセリフが作れるようになります。
高速マルチモーダルがあるから成立する話で、発話中の数秒間に数回分のキャプチャ → テキスト化を終わらせられるのがポイントです。
案3: テキストで状態が取れるゲームを選ぶ
ここまでは「人間がプレイする映像にAI実況を付ける」話でしたが、3つめは視点を変えて、AIがゲームのプレイ自体も担当するアプローチです。
冒頭で紹介したシステムでは、マルチモーダルAIで画面を解析して操作を決め、Arduinoでコントローラー入力をエミュレートする仕組みでプレイしていました。
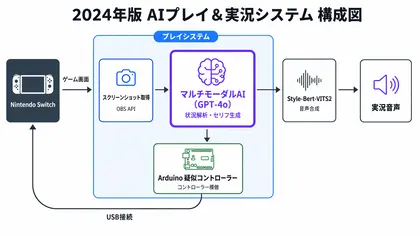
この仕組みには課題がいくつもありました。
マルチモーダルAIの処理で1ターンに30秒以上かかるうえ、ゲームごとに画面の状態や操作方法をあらかじめDBとして手動で用意する必要があります。
また画面認識が一度失敗すると詰まってしまうリスクもあり、安定して動かすのが難しい構成でした。
これらはすべて、「画面をマルチモーダルAIで解析する」ことへの依存から来る問題です。
オセロ・チェスのように、盤面や状態をテキストで取得できるゲームを選べば、このパイプラインが丸ごと不要になります。
実況も同様で、画面を解析する必要がなく、テキストのログをそのまま使えます。
まず試したのは、ゲーム自体を自作してしまうアプローチです。
Vibe codingの普及でゲームを作ること自体のハードルが下がった今、テキスト前提の設計を最初から組み込んだゲームを作るのは以前より現実的な選択肢になっています。
自作ゲームなら、情報のやり取りをゼロからテキスト前提で設計できます。
操作も実況セリフもLLMの出力をそのまま解釈して処理するので、画面認識由来の遅延や誤認識が入り込む余地がありません。
既存のゲームでも、状態をテキストで取得できるものなら同じことができます。例えば Pokémon Showdown です。
Pokémon Showdown はブラウザで動くポケモンバトルシミュレータです。
実機やROMを使うエミュレータとは異なり、バトルのルールをゼロから独自実装したもので、ゲーム内の情報がすべてテキストプロトコルでやり取りされる のが特徴です。
自分の手持ち、相手の場の状況、ターンの流れ、選ばれた技、これらすべてがテキストとして取得できます。
画面中央のログを見ると、盤面の状況が全部テキスト化されているのが分かります。
AIに画面を見せる必要がないので、テキストをそのまま LLM に渡して、技を選んで返してもらうだけでプレイが成立します。
そのログを使って実況させれば、プレイと実況を同じシステムで一気に解決できます。
研究界隈でも LLM にポケモンバトルを遊ばせる題材として定番になっていて、PokéLLMon や PokéChamp といった論文が出ています。
このやり方の強みは次の通りです。
- マルチモーダル不要なので 超高速
- 渡すトークン数が少ないので 超低コスト
- そもそも画面認識ミスという概念が存在しない
- ゲーム固有の画面DBを作らなくていい
- プレイと実況が同じシステムで完結する
弱点は、この方式の強みを活かせるゲームが限られることです。
もちろん、テキストログが取れないゲームでも、OCR・画像認識・メモリ読み取り・Mod・API連携などで状態を取得したり、操作を送ったりする方法はあります。
ただしその場合は、ゲームごとの実装難易度や安定性の差が大きくなります。
案3で紹介しているように、マルチモーダルに頼らず高速・低コスト・安定動作を狙うなら、テキストや構造化データとして状態を取得できて、操作もコマンド化しやすいゲームを選ぶのが現実的です。
「任意のゲームをそのまま遊ばせたい」用途には、まだあまり向きません。
「じゃあどのゲームでどういう状態取得や操作の手段が使えるの?」という部分をもう少し整理した続編記事も書いたので、気になった方はこちらもどうぞ。

終わりに
というわけで、昔と今でAIにゲームを遊ばせる構成がどう変わったかを書いてみました。
3つをまとめるとこんな感じです。
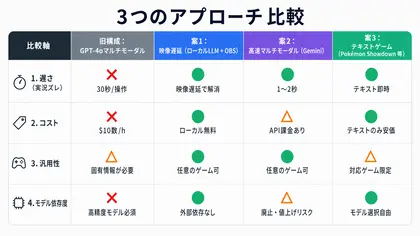
目的に応じて選べるのが今の強みです。
実装難易度で見ると、まず試しやすいのは案2、既存構成を活かしつつ長時間運用しやすいのが案1、ゲーム選定やシステム設計まで含めて一番作り込みが必要なのが案3です。
- まずは最短で試作したい → 案2
- コストを抑えて長時間運用したい → 案1
- 人間がプレイする映像にAI実況を付けたい → 案1か案2
- AIにプレイも実況もやらせたい → 案3が有力。対応しやすいゲームは限られる分、できたときの完成度は高い
1年半前に同じことをやっていた頃は「これ本当に高速化できるのか…?」と結構本気で悩んでいたんですが、今は選択肢のほうが多すぎて迷うレベル。最高の時代ですね。
皆さんもAIにゲームを遊ばせる系、興味があればぜひ遊んでみてください。
宣伝
2026年5月6日(水)に開催される 生成AI何でも展示会 vol.5 に出展します!
旧システムを初めて公開したのも同じこの展示会(vol.2)だったので、1年半でどれだけ変わったかを実際に見てもらえる場になればと思っています。
今回紹介した3つのアプローチのどれかをデモとして動かす予定なので、興味がある方はぜひ来てみてください。
また、普段XでAIツールやAIキャラクターについての発信をしているので、興味があったらフォローしていただけると大変喜びます🙇♀️